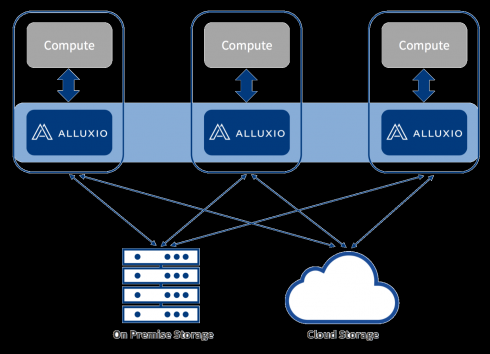
The open source, memory speed, virtual distributed storage solution Alluxio has reached version 2.0 and is now available as a preview release.
According to the company, Alluxio 2.0 is the “most ambitious platform upgrade since the inception of Alluxio.” Alluxio 2.0 includes the most new open-source features since the project was created, enabling the community to experiment with new capabilities, as well as explore new use cases, such as simplified data engineering and access for AI model training, the team explained.
The latest version will offer features to address challenges in three key areas:
- Supporting hyperscale data workloads with support for over 1 billion files, the introduction of Alluxio Job Service, a new feature for configuring data ranges, and a new fault tolerance and high availability mode.
- Enabling machine learning and deep learning workloads on any type of storage with the addition of the Alluxio POSIX compatible API, which allows frameworks like TensorFlow, Caffe, and other Python-based models to access data from storage systems.
- Providing better storage abstraction with support for multiple HDFS versions and active sync with Hadoop.
“Today, our users already deploy Alluxio at very large scale with many thousand node single cluster production deployments across telecommunications, retail and internet companies,” said Haoyuan Li, CEO and co-founder of Alluxio. “This release allows our users to take Alluxio deployments to the next level of scale with support for extreme data requirements. Our users as well as the data engineering community will find a much more intuitive interface with greatly expanded capabilities to help them run analytics and AI workloads on private, public or hybrid cloud infrastructures leveraging valuable data wherever it might be stored.”