Disasters are unavoidable and can cause irreparable damage to enterprises’ technical infrastructures. For organizations, this damage can turn out to be more monetary and reputational as they can lose data and clients. Thus, organizations usually have backup servers and recovery data centers as the first-response strategy. However, building resilience in this way is both costly and challenging. This article covers how disaster recovery and business continuity can be done on the cloud using the AWS recovery model in a multi-region environment.
In September 2018, a powerful lightning storm interrupted the power grid of Microsoft’s data center in Texas. As a result, several pieces of equipment were damaged, and its Teams services went offline for a full day. Companies in the United States can face more than $12 million in losses with 24 hours of downtime. Microsoft was lucky not to suffer data loss, but such power grid failures have caused massive data losses to other companies.
Downtime is one of the leading causes of data loss but not the only one. Organizations can face several disaster events that can cause interruptions in their operations including natural calamities like floods and human actions like unauthorized modifications or hacking.
While these disasters cause temporary service disruption, data loss can have long-term damaging impacts on operations and productivity in an organization. While most IT problems can be addressed with preventive measures to appease challenges, disasters are large-scale and inevitable. The only escape is to recover what is lost and flip the switches to restart disrupted services as soon as possible to minimize losses.
Organizations can keep redundant data centers for recovery and build resiliency for business continuity. A resilient site would typically have a passive site as its replicate that can be used to restore services quickly in case of the failure of an active data center. This, however, requires huge investments that go into maintaining redundancy. Amazon Web Services (AWS) provides a well-architected solution for this with built-in resiliency and multiple disaster recovery strategies to address outages.
AWS strategies for Disaster Recovery and Business Continuity (DRBC)
AWS strategies for DRBC are developed considering 2 parameters:
- RTO (Recovery Time Objective)
- RPO (Recovery Point Objective)
RTO reflects the duration in which the business process must be restored after the disaster in other words it tells the extent of downtime an organization can afford. RPO measures the maximum amount of data loss an organization can withstand after a recovery from a disaster. Depending on the acceptable trade-offs between RTO and RPO, 4 DR strategies can be formulated. The selection of an appropriate strategy depends on the criticality of the workload and AWS picks server instances to fit the workload.
Backup and Restore: In this approach, data is restored from the backups after a disaster event. It is usually applied in cases of data loss or corruption but can also be used in the cases of regional disasters to mitigate the lack of redundancy in a single Availability Zone (AZ). However, this approach has a risk of increased recovery times unless the infrastructure is deployed using infrastructure as code (IaC) with services like AWS Cloud Development Kit (CDK).
Pilot Light: This approach provides resources and scale-up after a disaster event through replication of data between regions. Application servers already have codes and configurations but are only switched on when a failure occurs, and recovery is needed. As resources are always available, fast provisioning of the full-scale production environment is possible.
Warm Standby: In this approach, the resources that are fully functional but not used are scaled-up after a disaster event. The recovery is fast and easy. It is somewhat similar to pilot light, which also has resources available, but in pilot light servers must be turned on and deployed before the takeover, unlike the warm standby approach that allows resources to take control immediately.
Multi-site Active/Active: AWS provides an active/active setup to support business-critical services that require zero downtime or near-zero data loss. Moreover, these strategies are multi-regional with data centers distributed in separate AZs. Several resources are provided to deliver business assurance against disasters across regions. Between standby and active/active multi-site approach also sits hot standby active/passive strategy in which users are directed to a single AZ and not DR regions. This approach is more economical while the active/active configuration is more resilient.
This approach allows the creation of highly available well-architected workloads that span AZs to achieve greater fault tolerance. There are three general benefits of expanding beyond a single region:
- Expansion to a global audience as an application grows and its user base becomes more geographically dispersed, there can be a need to reduce latencies for different parts of the world
- Reducing RPO and RTO as part of the DR plan
- Local laws and regulations may have strict data residency and privacy requirements that must be followed
Implementation: The multi-site active/active strategy is the most appropriate DR strategy when you need DR with the quickest recovery time (lowest RTO) and least data loss (lowest RPO). Implementing it across regions is a good option if you are looking for complete independence on your sites and low latency for users in globally diverse locations. Multi-region DR strategy can be implemented in AWS using AWS regions, Availability Zone, and services like Route 53 and Elastic Load Balancer. The data is synchronously replicated between multiple regions in S3, RDS, Aurora, and DynamoDB. When implementing multi-region active/active in AWS, you can also choose a routing policy and the right read/write pattern for your workload.
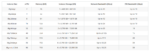
| DR Strategy | AWS Services |
| Backup and restore |
|
| Pilot Light | |
| Warm Standby |
|
| Multi-site active/active |
|
However, a multi-region strategy is both complicated and expensive. If you run a full-capacity redundant system on a secondary site, it will add considerable operating expenses to an enterprise. These costs include extra maintenance, extra staffing, downtime costs, and lost business. These costs can be hard to swallow when expected returns on infrastructure investments prove elusive.
While there are challenges to the implementation of the multi-region DR strategy, if you choose to implement it for its obvious benefits, here are a few recommendations for you
- Implement CIS Benchmark guidelines
- Adopt a strong DevOps practice by deploying the multi-region workloads using Infra-as-a-code and CI/CD.
- Adopt managed services with containerized architecture or serverless architecture
- Perform Chaos Engineering
- Perform dry-run and ensure the workload availability after a disaster
- Perform game days periodically
What’s Your Disaster Recovery Strategy?
Any IT system is known to experience outages, and Amazon Web Services is like any other. The difference is that AWS is built for resiliency. AWS has multiple disaster recovery strategies to address the outages on a need basis based on RTO and RPO. Like an insurance policy, there are expenses to consider including maintenance, time, and staffing. But having a disaster recovery strategy in place will spare you the cripple consequences of being unprepared when catastrophe strikes.